
In 2011, the phrase “software is eating the world” captured how digital tools were reshaping industries. Today, with the rise of generative AI (Gen AI), the center of gravity is shifting back to hardware—the chips and infrastructure that power AI models. Software remains essential, but the ability to build, scale, and deploy powerful AI now depends on the hardware it runs on. Compute is no longer in the background; it is defining what AI can achieve and how fast it can advance.
Breakthroughs in AI, particularly Gen AI, are fundamentally limited by hardware. Large-scale models such as GPT, multimodal systems, and image or video generators require immense computational power to train and deploy. The pace of innovation is directly tied to advances in GPUs, tensor processing units (TPUs), and custom accelerators. The real question isn’t just what models can we build, but whether we have the compute infrastructure to support them. Models can only grow as powerful as the chips, memory systems, and data center networks sustaining them.
Hardware has become the new strategic battleground. NVIDIA continues to dominate with its GPUs, but competition is intensifying. AMD, Intel, Meta, Google (TPUs), AWS (Trainium, Inferentia), Microsoft (Maia), and specialized startups like Cerebras and Groq are pushing the boundaries of scale and efficiency. Each new generation of chips reduces costs, boosts speed, and unlocks new AI applications.
For example, NVIDIA’s HGX B300 and RTX PRO™ 6000 Blackwell Server Edition GPUs are driving a shift from CPU-based systems to accelerated computing platforms, enabling enterprises to harness higher performance and efficiency. Meta, meanwhile, introduced its own Meta Training and Inference Accelerator (MTIA) to improve compute efficiency and support AI model development.
Hyperscalers are pursuing a full-stack strategy—building AI-optimized infrastructure across three integrated layers: purpose-built hardware, foundation models, and orchestration tools. For instance, on the hardware front, Google recently introduced Ironwood, its seventh-generation TPU, while AWS continues to expand the adoption of its Trainium chips.
At the foundation model layer, Google launched its latest Gemini 2.5 Pro and Flash models, while Microsoft is scaling enterprise access to OpenAI models via Azure. To complete the stack, orchestration tools are becoming central; Google has rolled out Agentspace alongside Vertex AI, while AWS provides the Neuron SDK to optimize workloads across its custom chips. Together, these examples highlight how hyperscalers are tightly integrating innovation across the stack to deliver differentiated AI platforms.
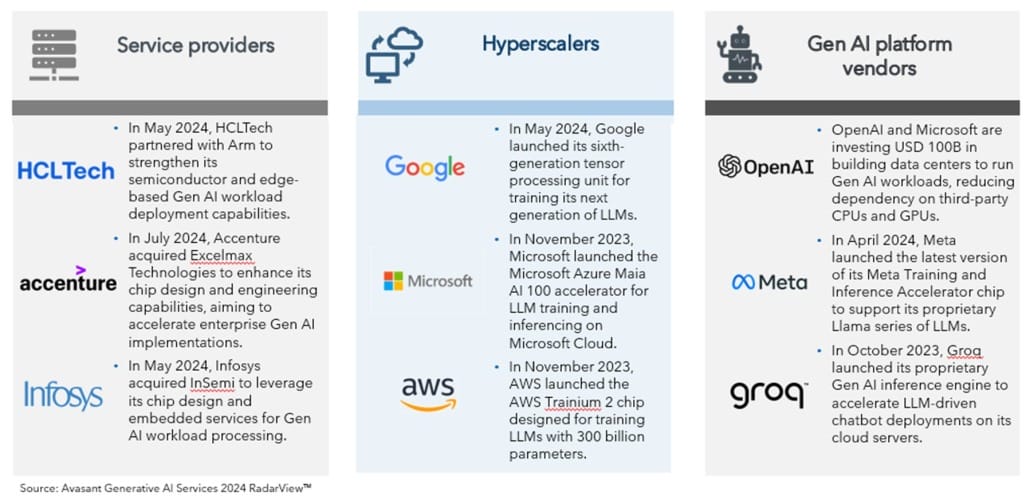
Even the leading service providers are making bold moves to strengthen chip capabilities:
This trend was captured in Avasant’s Generative AI Services 2024 RadarView™ (see Figure 1).
The AI hardware race doesn’t stop at chip design; it extends into infrastructure, supply chains, and geopolitics.
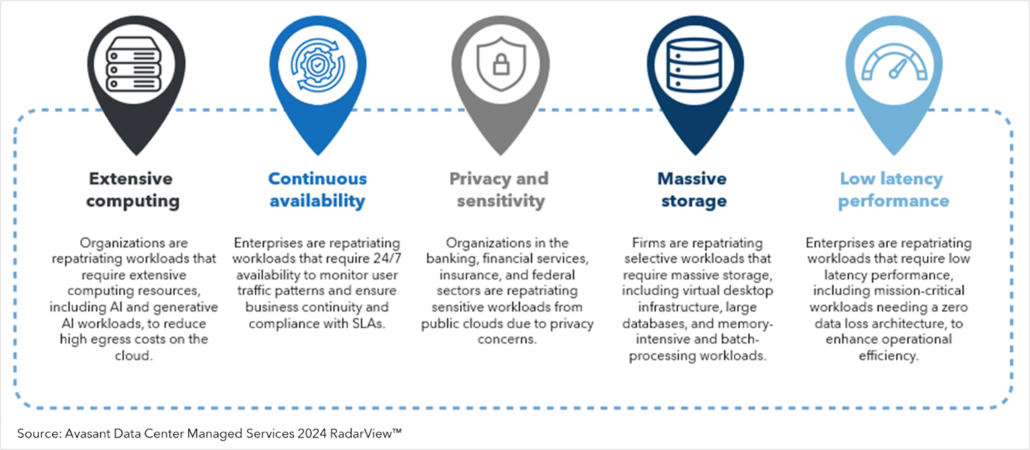
AI accelerators consume enormous energy. With data volumes surging, compute demand is outpacing power supply. Enterprises face a widening gap between energy needs and availability, forcing data centers to rethink their architecture and consider investments in energy-efficient designs, renewable sources, and advanced cooling systems. Cloud repatriation is also on the rise (see Figure 2), as enterprises seek tighter control over AI workloads.
In our research byte “Optimizing Power Consumption in Data Centers in the Age of AI,” we examine various ways organizations leverage AI to optimize energy consumption and apply cooling techniques in data centers.
At the same time, global supply chains for semiconductors are under severe strain. Key pressure points include:
While governments are pursuing regionalization through the US CHIPS Act, the EU Chips Act, and India’s semiconductor mission, these efforts also create inefficiencies. The result—hardware resiliency, not just software innovation—is emerging as the key bottleneck in scaling Gen AI.
Yet even as this hierarchy solidifies around access to massive compute, an alternative path is emerging. The future of AI may not be defined solely by how much infrastructure can be amassed, but also by how intelligence can be delivered more efficiently at smaller scales.
The software-centric era of the past decade enabled startups to scale rapidly using open-source tools and relatively modest infrastructure. In contrast, the Gen AI era is being defined by massive capital investments and access to scarce compute resources. The ecosystem is now splitting into three distinct groups—model builders, model users, and hardware providers—each playing a different role in shaping the future of AI innovation:
This new hierarchy is reshaping the power dynamics of tech. Capital-intensive, infrastructure-rich players are pulling ahead, while smaller innovators must navigate rising barriers to entry.
While today’s Gen AI breakthroughs are tied closely to LLMs running on massive GPU clusters, this compute-heavy approach may not scale indefinitely. Training trillion-parameter models requires extraordinary energy and infrastructure investments that are unlikely to be sustainable in the long run. Already, an alternate paradigm is emerging with lightweight AI models that can achieve meaningful intelligence with far fewer parameters and can even run on small, edge devices.
These small language models (SLMs), such as Microsoft’s Phi family of SLMs (Phi-3 and Phi-4), Meta’s quantized versions of Llama 3.2 1B and 3B, and Google’s Gemma lightweight models, are designed for efficiency, balancing performance with a small computational footprint. Startups are also innovating in chip-optimized AI offerings, such as d-Matrix’s CorsairTM compute solution for AI inference at data centers and Edge Impulse’s TinyML platform, which builds datasets, trains models, and optimizes libraries to run directly on any device.
At the hardware layer, companies are experimenting with neuromorphic chips (Intel Loihi 2) and AI accelerators that mimic brain efficiency. Apple has already embedded dedicated neural engines within its consumer devices. This shift signals a future where AI does not necessarily require large data centers, but instead becomes distributed, running locally on chips in everything from smartphones to IoT devices.
The co-evolution of software and hardware is progressing along two key trajectories: the development of ever-larger, compute-intensive frontier models, and the advancement of highly efficient, small-scale models tailored for specific, decentralized applications. Together, they represent the dual track of the AI revolution. The future may not be defined by how big models can grow, but by how intelligently they can shrink.
By Gaurav Dewan, Research Director and Asmita Gaur, Research Intern