
Video generation technology has undergone multiple evolutionary leaps. In the 2010s, convolutional neural networks (CNNs), a deep learning algorithm, revolutionized the ability to classify and analyze images, spreading its applications across facial recognition, medical imaging, and more. In 2014, generative adversarial networks (GANs) emerged, another deep learning algorithm capable of creating realistic images but limited to simpler tasks like anime creation, face swapping, and basic video analytics due to the lack of context understanding and gesture synchronization.
Despite these advances, the mass commercialization of AI video generation tools has faced significant challenges. Applications were restricted to a few images, heavily reliant on ML engineers, and plagued by lengthy model training cycles and substantial training data requirements. Early AI-driven video applications were also prohibitively expensive; for example, the visual effects for face-swapping Paul Walker in the “Fast and Furious” franchise cost around $50 million.
In late 2022, the landscape changed dramatically with the introduction of large language models (LLMs) that opened up a new market for cost-effective text-to-video generation capabilities. This enabled mass adoption through a natural language interface. Startups like Runway and Pika Labs brought sophisticated video generation to a broader audience. However, challenges like photo-realism, visual clarity, stability, video customization, long-form video creation, and prompt adherence remained.
On February 15, 2024, OpenAI shook the market with the launch of Sora, an advanced text-to-video generation tool. Sora outperformed its predecessors by supporting long-form video creation of up to two minutes and producing hyper-realistic videos with meticulous visual details. It also demonstrated an improved emotional and contextual understanding of prompts. While the industry eagerly anticipates Sora’s commercial launch, the market is rapidly evolving. Sora is just the beginning, with new solutions emerging to push the boundaries further, such as the following:
With the recent unveiling of GPT-4o and its advanced multimodal input and output capabilities, enterprises face a critical question: is there a need for a standalone Gen AI video generation platform? The answer is a resounding yes, and here’s why:
So, despite the rise of multimodal AI like GPT-4o, standalone text-to-video generation platforms will continue to thrive. Their domain-specific customizations, extensive visual libraries, competitive pricing, higher accuracy levels, and comprehensive editing features remain indispensable for enterprises seeking high-quality, tailored video content.
Video generation tools like Sora and Mora (an open-source text-to-video generation platform) drive a transformative shift in enterprise applications far beyond traditional movie production and scene generation. As these tools become more cost-effective and sophisticated, with enhanced semantic coherence and prebuilt customizations, their applications rapidly expand across various industries.
Educational institutions are leveraging these tools to create more interactive and engaging videos, revolutionizing the learning experience. The film and television industry uses them to efficiently generate complex scenes, saving time and resources. Advertisers are crafting personalized advertisements with ease, all through simple text commands.
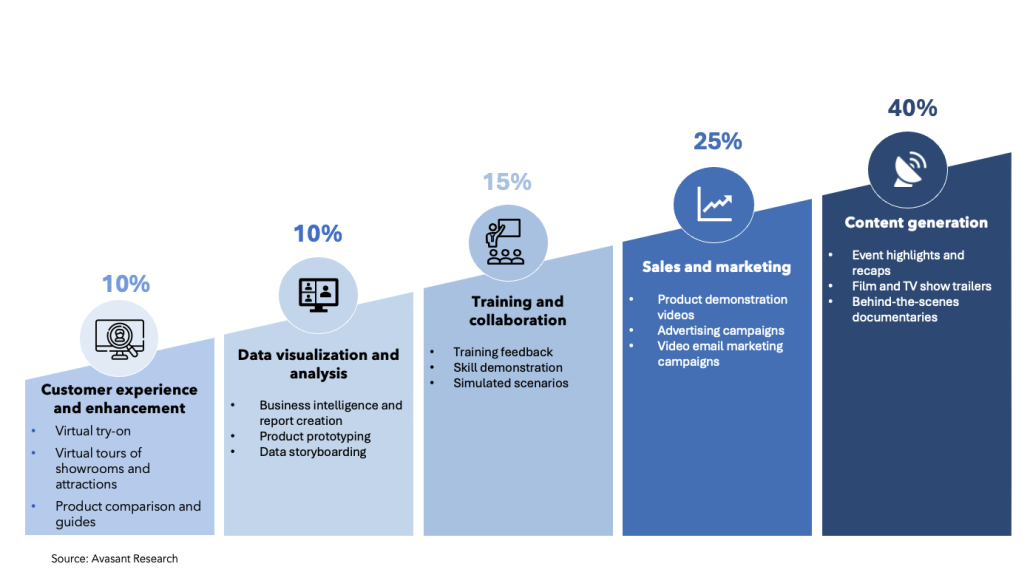
This technological advancement is not just an incremental improvement; it represents a dramatic leap forward in creating and consuming video content. Enterprises across sectors can now harness the power of text-to-video generation tools in unimaginable ways, leading to a new era of innovation and creativity.
Although text-to-video platforms have garnered significant interest and are poised to become indispensable, they also bring inherent risks. Therefore, enterprises must establish robust governance and risk strategies to mitigate the following threats posed by these tools:
Enterprises must thoroughly examine the vendor’s data security and privacy measures when sourcing a text-to-video platform. For instance, OpenAI plans to embed Coalition for Content Provenance and Authenticity (C2PA) metadata watermarks to content generated through Sora, alongside an advanced content moderation system. These vendor-provided safeguards can mitigate initial risks but are not sufficient on their own. Security threats can escalate quickly; for example, less than 12 hours after its release in June 2024, Luma AI’s Dream Machine, a generative AI model capable of producing high-quality videos from text and image inputs, was jailbroken.
Thus, enterprises must establish a robust internal governance policy with explicit guardrails. This policy should ensure continuous monitoring of AI-generated content and verify alignment with company policies and global AI guidelines. By proactively addressing these risks and implementing comprehensive governance and risk management strategies, enterprises can harness the power of text-to-video tools while safeguarding their integrity and trust.
However, some external risks beyond an organization’s control can arise with technological advancements, especially as malicious actors gain access to sophisticated tools. One such significant risk is misinformation through deepfakes, leading to credibility issues. Advanced text-to-video tools can create high-quality deepfakes, which can be used for carrying out scams, impersonating CEOs, and creating fraudulent content. Enterprises should implement detection algorithms and use emerging tools such as Sentinel and Sensity to detect deepfakes. Legal and compliance issues may also arise, as deepfake videos can falsely implicate a company, leading to legal battles and regulatory scrutiny. To counter this, enterprises should adopt blockchain verification and digital watermarking and train employees on deepfake risks, verification protocols, and legal preparedness to address such content.
By Chandrika Dutt, Associate Research Director, Avasant, and Abhisekh Satapathy, Lead Analyst, Avasant